Blog

Unlock our latest insights today
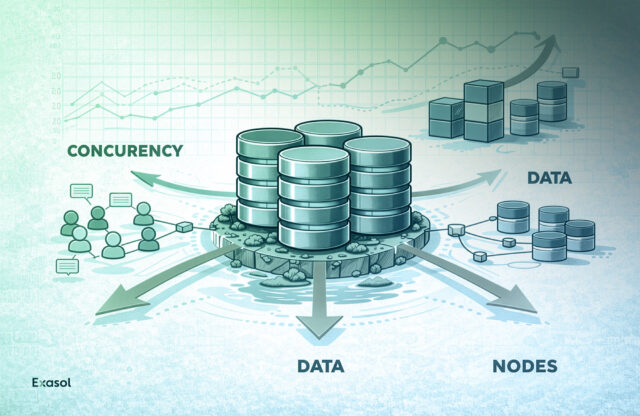
Five analytical databases. Three scalability dimensions. One reproducible TPC-H benchmark. We tested Exasol, ClickHouse, StarRocks, Trino, and DuckDB across concurrency, data growth, and cluster size to see what actually happens when workloads scale.
Continue reading
Discover how the dbt-exasol adapter combines dbt’s transformation framework with Exasol’s high-performance analytics engine. Build fast, scalable data pipelines without compromising on developer experience or speed.
Continue reading
Learn everything you need to know about process mining with Exasol. Real demo and an open-source project to start testing.
Continue reading
In today’s data-driven world, businesses are no longer satisfied with insights that arrives hours—or even minutes—too late. Real-time data streams from applications, IoT devices, and event-driven systems demand analytics platforms …
Continue reading
Why database benchmarks often mislead: a real-world scalability test reveals how query failures and concurrency, not speed, define true analytical performance.
Continue reading
Learn how Exasol Virtual Schemas enable flexible, hybrid deployments with on-demand data access, schema refresh, and minimal ETL overhead.
Continue reading
The Problem with Database Benchmarks I have been running database benchmarks for years, and the same problems kept coming up. Missing configurations. Unreproducible results. Vendor claims that nobody could verify. …
Continue reading
Accelerating Innovation, Expanding Possibilities Building on the foundations of Exasol Release 2025.1, we now take the next leap with Exasol 8 Release 2025.2: unleashing context-rich AI, personal big data analytics …
Continue reading
Democratizing Big Data Analytics The field of analytics has been blessed with good tools recently. If you are working with a set of data that fits on a single machine …
Continue reading
valantic’s proposition is action over abstraction. They embed with your First Line to wire up real workflows and train teams so compliance outlives the project. Their track record recertifying 600+ …
Continue reading