Text to SQL: Local, Secure, and Smarter

At Exasol, we are constantly exploring new ways AI can help users get the most value out of their data. In a recent blog post we shared an approach to a Text to SQL application. This application converts natural language to SQL queries – lowering the barrier of entry for users. Now, we’ve improved upon this design by implementing the application in a way that all data or metadata will not leave the user’s premise, so we meet enterprise level security requirements.
You can execute Large Language Models (LLM) locally within your infrastructure, such as Ollama (https://ollama.com) or LM-Studio (https://lm-studio.ai). We chose LM-Studio because it runs very performantly on an Apple M4 MAX, particularly when loading LLMs in the MLX format.The MLX format is a relatively new open-source AI/ML software stack from Apple, explicitly optimized for Apple Silicon chips. LM-Studio supports the OpenAI API, making it compatible with other server solutions. With this setup, you are fully self-sufficient in deploying and utilizing LLMs. I have also been asked whether inferring the LLM directly in the database is possible, as it generates SQL statements. The answer is yes, but it also depends. While LLMs in databases are typically used for processing hundreds of thousands of records or documents, SQL-generating LLMs account for only a tiny portion of the overall load in the database but may necessitate larger LLMs. You might block resources of the databases for a tiny portion of the overall database load. This is a decision someone has to make individually. If you have more fixed reports and dashboard which change only rarely, SQL statements should be created outside of the database. If you have a use case which support ad-hoc with unknown questions to the database for a wider user group reporting it makes sense to deploy the Text-to-SQL transformation process into the database.

Try Exasol for Free
Test the full power of Exasol’s Analytics Engine for free. Download our Community Edition and start exploring today.
Effective Prompt Engineering
To generate valid SQL statements, you must provide the LLM or the LLM server with contextual awareness of your database – including information such as schema, table, column names and column comments. This practice is called Prompt Engineering, where you supply additional information beyond your question in natural language. The more information you provide, the better the final result. Meaningful names for table columns that represent metrics, dates and times, objects, or locations will enhance the quality of the result. Using comments for database objects can offer valuable hints to the LLM, such as indicating the content format in a specific column. The columns used for joining tables should have identical names to achieve the best results for generating table joins. If you do not have a good database design per the above rules, consider adding a view layer that implements them.
In the prompt we will also inform the LLM about the SQL dialect being used by the source database. For Exasol, it’s advisable to instruct the LLM to use the Oracle SQL dialect.
Sometimes, the line between success and failure in creating a valid SQL statement is thin. For each new natural language question, a similarity search in a vector database can identify existing SQL statements and their corresponding questions that are identical or similar to the new inquiry. It is essential to filter based on a practical distance between the new question and those already stored in the vector database. Otherwise, the LLM may be misled regarding the new SQL statement that needs to be created.
You must do the Prompt Engineering separately for each database schema if you have several different schemas. While most parts of the Prompt Engineering are the same – reflecting the behavior of your database – details of individual database schemas need to be included in the prompt engineering, e.g. specific formats or metric descriptions.
The final goal is to create an SQL statement on the first attempt without having an agent who automatically tries to alter the statement if the created SQL statement turns out to be syntactically wrong.
Let’s dive in and see how everything is being accomplished. We will use a relatively simple database schema for a retail demo use case, fitting perfectly for demo purposes.
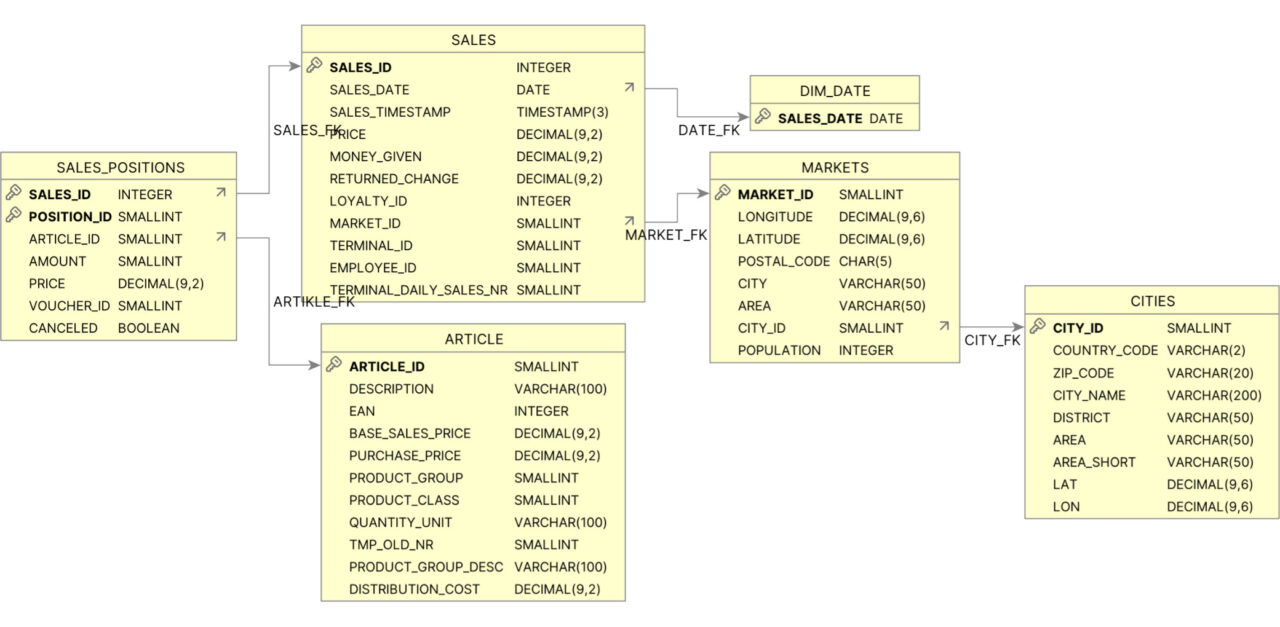
First, we need to obtain the database schema metadata. We should fetch the schema dynamically to ensure that the most recent changes are incorporated into the system prompt during SQL statement creation. Examples of these changes may include added columns, modified data types, or comments related to the table or its columns. A code fragment for a function coded in Python, retrieving the schema metadata for an Exasol database, is shown below:
with pyexasol.connect(dsn=dsn,user=user,password=passwd,schema=schema)as con:
query = f"""
SELECT
COLUMN_SCHEMA,
COLUMN_TABLE,
COLUMN_NAME,
COLUMN_TYPE,
COLUMN_COMMENT
FROM
SYS.EXA_ALL_COLUMNS
WHERE
COLUMN_SCHEMA IN {working_schemas}
ORDER BY
COLUMN_SCHEMA ASC, COLUMN_TABLE ASC"""
stmt = con.execute(query)
schema_metadata = ""
table, old_table = "", ""
for row in stmt:
schema = row[0]
table = row[1]
if table != old_table:
schema_metadata += f"\n Table '{schema}.{table}': \n Columns: \n"
if row[4] is None:
comment = "No comment"
else:
comment = row[4]
schema_metadata += "\t - "+row[2]+": "+row[3]+' :: '+comment + "\n"
old_table = table
return schema_metadataThe result will be added transparently to the prompt for the user. We need to instruct the LLM on what the task is and augment this information with some details about the environment:
You are a helpful assistant for data analytics.
Create a raw SQL Statement without any description, based on the provided
schema. The target is an Exasol Analytical database. In doubt use an
Oracle SQL dialect.Interestingly, telling the LLM / LLM server to return only the generated SQL statement was necessary. Otherwise, it would return explanations for each step during the SL creation. This might be helpful for educational purposes, but it was not the goal of this exercise. The generated SQL statement needs to be executed immediately to check for the correct syntax and to see if it returns results. The format of how how the SQL statement is embedded in the answer varies between different LLMs. You must extract the raw SQL statement before sending it to the database for testing. We accomplish this using a regular expression:
match = re.search(r’.*((DELETE|SELECT|UPDATE|WITH)(.+|\n)*);\n’, answer)The expression works for most SQL statements, including Common Table Expressions (CTE). It does not support the creation of objects.
Finally, we query the vector database for similar natural language questions and seek to identify an SQL statement that could assist the LLM. For this application, we chose Chroma since it embeds easily in your Python code and does not require additional servers to be started.
Now comes the tricky part: you must engage in prompt engineering, which you must implement as corrective measures when SQL statement generation fails. This is interactive work and is, therefore, different from the previous steps, where the prompt was augmented either statically in the code or dynamically, e.g., the schema metadata by the code. With trial and error – by actually testing various scenarios – we discover additional prompts to add to our list to help ensure our app generates correct SQL.
Let‘s look at a simple example:
In Exasol, a column name will be stored or referenced in uppercase. If the database schema contains a column name in lower case or a mixture of upper and lower case, you must embed the column name in double quotes. The statement
SELECT DISTINCT
"Manufacturer Name"
FROM
exasol_dib_semantic_layer_test.attribute_sample_values
WHERE
City like 'WOODBURY';will fail because the database cannot find the object CITY. To correct this, we’ll add the follow instruction to our prompt:
Encapsulate column name with double quotesNow the LLM will produce the following SQL statement
SELECT DISTINCT
"Manufacturer Name"
FROM
exasol_dib_semantic_layer_test.attribute_sample_values
WHERE
"City" like ‚WOODBURY';which is syntactically correct; the database identifies the object CITY and will provide the correct result. Depending on the type of queries and the schema design, creating several guidelines for ad-hoc prompt engineering may be necessary. Once your model can satisfactorily answer your human questions, you can transfer these system prompts into your tool’s code or a file containing all the system prompts, which will be accessed for every translation.
The interaction with the LLM is done with an API call:
response = client.chat.completions.create(
model=state.selected_model,
messages=[
{"role": "system", "content": context},
{"role": "user", "content": prompt}
],
temperature=state.temperature
)The variable context contains the complete prompt engineering defined during the development process and the dynamically created prompt engineering, such as the automatically retrieved schema metadata. The prompt variable holds your natural language question, which needs to be translated into an SQL statement. We will search for similar natural text questions that have previously been successfully translated into an SQL statement to enhance the prompt further. We use a vector database that efficiently searches for similar formulated textual questions. SQL statements executed without errors are considered syntactically correct and stored in a Vector Database for future reference, together with the textual question. As an option, you can enforce the criteria for a „good“ SQL statement and store only those SQL statements in the Vector Database that return results, thus excluding SQL statements with empty result sets.
The following screenshot shows a prototype for a development bench for translating natural language queries into SQL statements. The development bench has been created as proof of concept and is not a finished nor an available product. It allows an interactive way to define the missing system prompts for your translation process for different database schemas and Large Language Models. It has been created with the „Taipy“ framework (https://taipy.io), which supports an easy way to build Python data-driven applications.
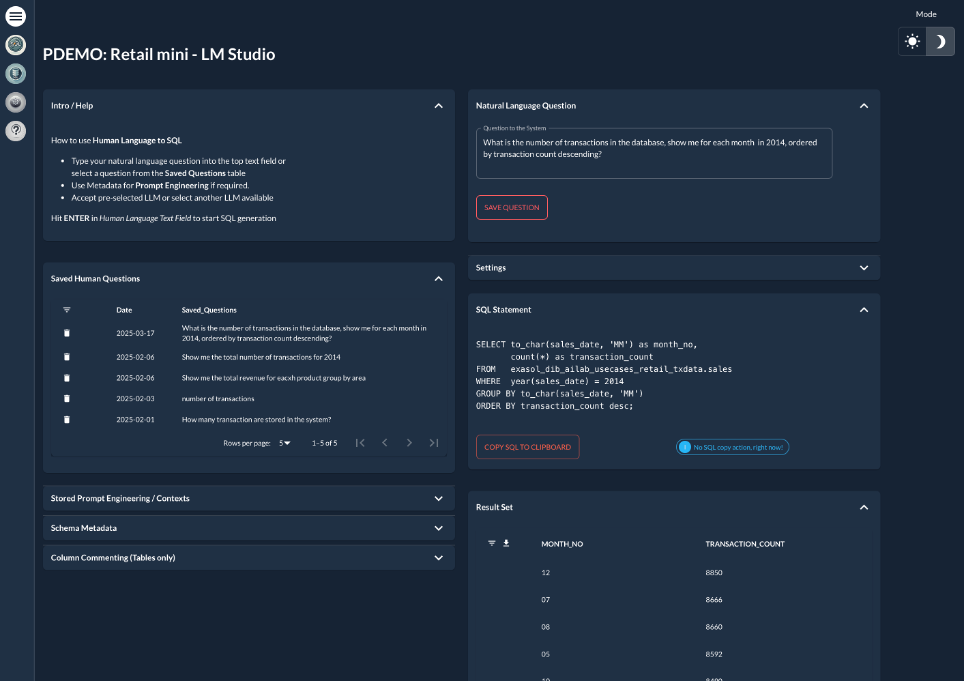
One of the most interesting discoveries was the variation in the quality of the created SQL statements depending on the Language Model we used. Some LLMs can be better instructed with user-defined system prompts than others. Experimenting with different models is beneficial. In our testing, a more generic instruct LLM outperformed an instruct LLM dedicated to SQL tasks concerning syntactically correct SQL statements.
Another challenge is determining and instructing the model on when to use GROUP BY and other aggregations. In our testing, this proved to be a more common error cause which we will continue to explore!
Individual prompt engineering is key to a successful translation process. It must be done for every different Large Language Model you are testing.
The overall success rate for creating syntactically correct SQL statements is quite high but does not reach 100 percent.
Overall, the results are pretty promising, showing that translation to SQL can be achieved without complex agents. In fact – creating the user interface proved to require more code that the SQL translation itself.
What’s Next for Text to SQL
Can we further enhance the SQL generation process? One way to improve the quality of SQL generation is by utilizing a semantic layer. This is particularly beneficial when the resulting query layer is flat, as this eliminates the need for joins that are inherently hidden under the hood and are not the end user’s concern.
Secondly, you can use the so-called Retrieval Augmented Generation (RAG) process to enhance the quality further. With this approach, documents or links to web pages are uploaded to the server or added to the prompt and utilized by the LLM to transform text into SQL statements. We are excited to continue refining and improving this solution – and we look forward to learning from you, our users – what would you like to see next?